In this article I’ll be discussing the benefits of using a consistent unknown member key across your data warehouse. And I’ll show you a couple of ways of going about implementing a consistent approach.
Each of your dimensions should have an unknown member key. The aim of which is to ensure all source data flows into your fact tables. When you load your fact tables you will typically be using your business key from the source of your fact data to match the same value from your dimension. When you’ve found a match, you can then get the surrogate key from your dimension (to see why you should always use surrogate keys see Tip #5).
If your dimension doesn’t have a value for the business key that you are trying to find, you have a problem. We want to allow the data to flow through so we don’t lose it, but if we leave our surrogate key value NULL then it’s going to break referential integrity. It also means you have to cater for nulls when joining between dimension and fact or risk your figures being inaccurate. This doesn’t bode well for an intuitive data warehouse or mart.
So the approach to take is to generate your own unknown member key in each dimension. This is essentially a catch-all for any fact records that don’t find a match in the dimension. Now when you do this I advocate standardising your unknown member creation, and using the same unknown key for each dimension in your data warehouse.
What should the value of your unknown member key be?
My standard unknown member key value is -1. I like it because it’s nice and obvious that it’s an unknown member if you’re ever viewing the raw data. However, I would actually advocate using 0 (zero), and here’s why. You will have some dimensions that have very few members. Think gender, or age for example. Each of these would happily sit within a TINYINT (0 to 255). However, if our unknown member key value is -1, this gives us a problem because this doesn’t sit in the range of TINYINT. So we have to go with SMALLINT (-32,768 to 32,767) purely because we like -1. Now data warehouses are less concerned about space than they are performance, but this is using space unnecessarily and it’s detrimental to performance. So use zero and then if it makes sense for your surrogate key to be a TINYINT then it can be one.
Creating your unknown member in your dimension
The creation of your unknown member is a straightforward process. I use SSDT for my data warehouse development, and I will have a script to generate all of my default data as part of my post-deployment scripts. These scripts run automatically after the database has been published through SSDT, and the scripts will run regardless of whether I’m publishing the database for creation or update. Here’s an example of what I do.
PRINT 'Loading unknown member into DimCurrency';
SET IDENTITY_INSERT DimCurrency ON;
MERGE INTO DimCurrency AS TARGET
USING (VALUES(0, 'UNK', 'Unknown')) AS SOURCE (CurrencyKey, CurrencyAlternateKey, CurrencyName)
ON TARGET.CurrencyKey = SOURCE.CurrencyKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (CurrencyKey
, CurrencyAlternateKey
, CurrencyName)
VALUES (SOURCE.CurrencyKey
, SOURCE.CurrencyAlternateKey
, SOURCE.CurrencyName);
SET IDENTITY_INSERT DimCurrency OFF;
Here I am setting my unknown member key to (my new favourite value of) zero. Being a surrogate key it can be any value you like (within the confines of the data type). It’s never going to be able to collide with another value unless you’ve started loading your business data before you generate your unknown member. To avoid this always create your unknown member as part of the process you follow for creating your table initially. Here I’m inserting into an identity column, but the same applies when you are manually maintaining the surrogate keys. You just don’t need to set IDENTITY_INSERT on or off.
Populating the unknown member key in the fact table
So now that you have created your unknown member in your dimension you can go and populate it when loading your fact table. Below is a simple example of how I do it in SSIS. I use lookup components to join from the relevant business key in the source data to the business key in the dimension. If I find a match I then retrieve the surrogate key value.
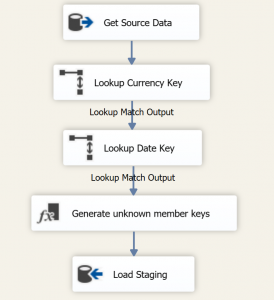
When you are using lookup components in this way you need to ensure that you select the “Ignore Failure” option when specifying how to handle rows with no matching entries in the General tab of the lookup component. This means that any records that don’t find a match in the dimension will continue to flow through the “Lookup Match Output”. We repeat this process for each dimension. Then I have a derived column component where I am allocating my unknown member key values.
In the screenshot below you can see how I do this.

I am checking to see if the dimension key is null and if so setting the value of the column to zero. If it isn’t null I’m setting it to it’s current value.
Setting your unknown member key value at the project level
Throughout this example I’ve been hardcoding my unknown member key value, however what if we want to change it when in the development phase? It’s going to be set in a number of scripts and packages, and it’ll be a pain to change them. So how about we set it at the project level?
Create a command variable (SQLCMD) in your DB project
Firstly, create a command variable in your DB project, as per the screenshot below.
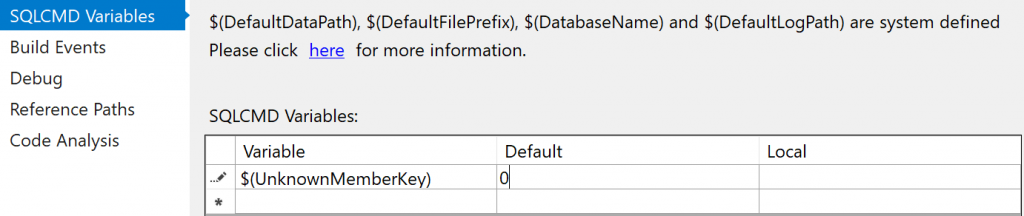
This allows you to do two things:
- Pass this command variable into any scripts or procedures in the DB project.
- Pass it to an execution of the SSIS package (via a SQL agent job creation script in your post deployment scripts).
Here’s the creation of our unknown member for our currency dimension with the inclusion of the command variable.
PRINT 'Loading unknown member into DimCurrency'; SET IDENTITY_INSERT DimCurrency ON; MERGE INTO DimCurrency AS TARGET USING (VALUES($(UnknownMemberKey), 'UNK', 'Unknown')) AS SOURCE (CurrencyKey, CurrencyAlternateKey, CurrencyName) ON TARGET.CurrencyKey = SOURCE.CurrencyKey WHEN NOT MATCHED BY TARGET THEN INSERT (CurrencyKey , CurrencyAlternateKey , CurrencyName) VALUES (SOURCE.CurrencyKey , SOURCE.CurrencyAlternateKey , SOURCE.CurrencyName); SET IDENTITY_INSERT DimCurrency OFF;
The script might complain in SSDT because it won’t like the $(UnknownMemberKey) in the middle of your merge statement, but the script doesn’t get built as part of the project and when the project is deployed it doesn’t complain and the value is replaced successfully.
Create a parameter in your SSIS package
Now you can create a parameter in your SSIS package.

And assign it when you set the value of the unknown member in the derived column component.

Any thoughts or questions please let me know.
Strange. I took the opposite direction. Zero used to be my favorite for the unknown member, with -1 representing the N/A if that was a valid choice. I occasionally ran into issues as a few dimensions had a valid 0 member. As SSAS doesn’t do well with the tinyint in SSAS, I’ve used the small int anyway. I wish SQL Server and SSAS had been on the same page about this. A tinyint of -126 to 127 would be just as useful to me as 0 to 255.
Because of those few issues, I’ve opted for -1 for the unknown and -2 for N/A if that’s an option. So far I’ve had no issues. As far as creation, it’s part of the table creation.
Hi Ron. Thanks for your feedback and for sharing your strategy. That’s a very good point about SSAS. I haven’t built a multidimensional model for a while, and had completely forgotten that was one of the reasons why I never used a tinyint for my surrogate key. I know you could convert it in the data source view of your SSAS DB, but it’s always nice keep the DW and the SSAS DB consistent wherever possible. I haven’t done much with the tabular model yet so I’m not sure if this is a limitation there as well.
You shouldn’t have any issues with a zero for your surrogate key though as you are in control of all of the values of it. It would only risk overlaping if you were using your business key as the primary key for your dimension rather than a surrogate key, and I wouldn’t recommend that (see tip #5 for my thoughts).
Hi Chris, nice post!
I happen to manage a multicompany data warehouse, with several different profiles for each of the 12 (and counting) companies, many of which can only see facts and dimensions filtered by the profile company.
Since the underlying ERP, from which most of the data come from, doesn’t enforce referential integrity, I used both the “empty” and “unknown” members, to represent the “not set/not available” and “set, but unknown” situations.
With the companies having CompanyKey from 1 to 12, I set both members for each company, using -CompanyKey (hence -12 to -1) for the empty members and -100-CompanyKey (hence -112 to -101) for the unknown members. Each dimension and each fact table have the CompanyKey, though, so each profile can easily see its company’s members without having to bypass the company filter.
This approach isn’t very scalable, but has worked for seven years, with five company acquisitions in the meantime.
Hi Alberto. Thanks for the feedback, and thanks for sharing your scenario and strategy. It looks like you’ve got a nice consistent approach there, and it has obviously stood the test of time. It’s always challenging with real world scenarios where things don’t quite work like the Microsoft examples, but this is where we earn our money :).